Rolling in the Deep: CNN
Introduction to Convolutional Neural Networks
Why we need CNN?
Assume that you have a dataset of cats and dogs, and you want to build a model that can recognize and classify them, given an unseen image of a cat or a dog.The first step is feature extraction, i.e. choosing the best features from your images, such as color, object edges, pixel location, etc. The second step is classification into cats and dogs using the extracted features.
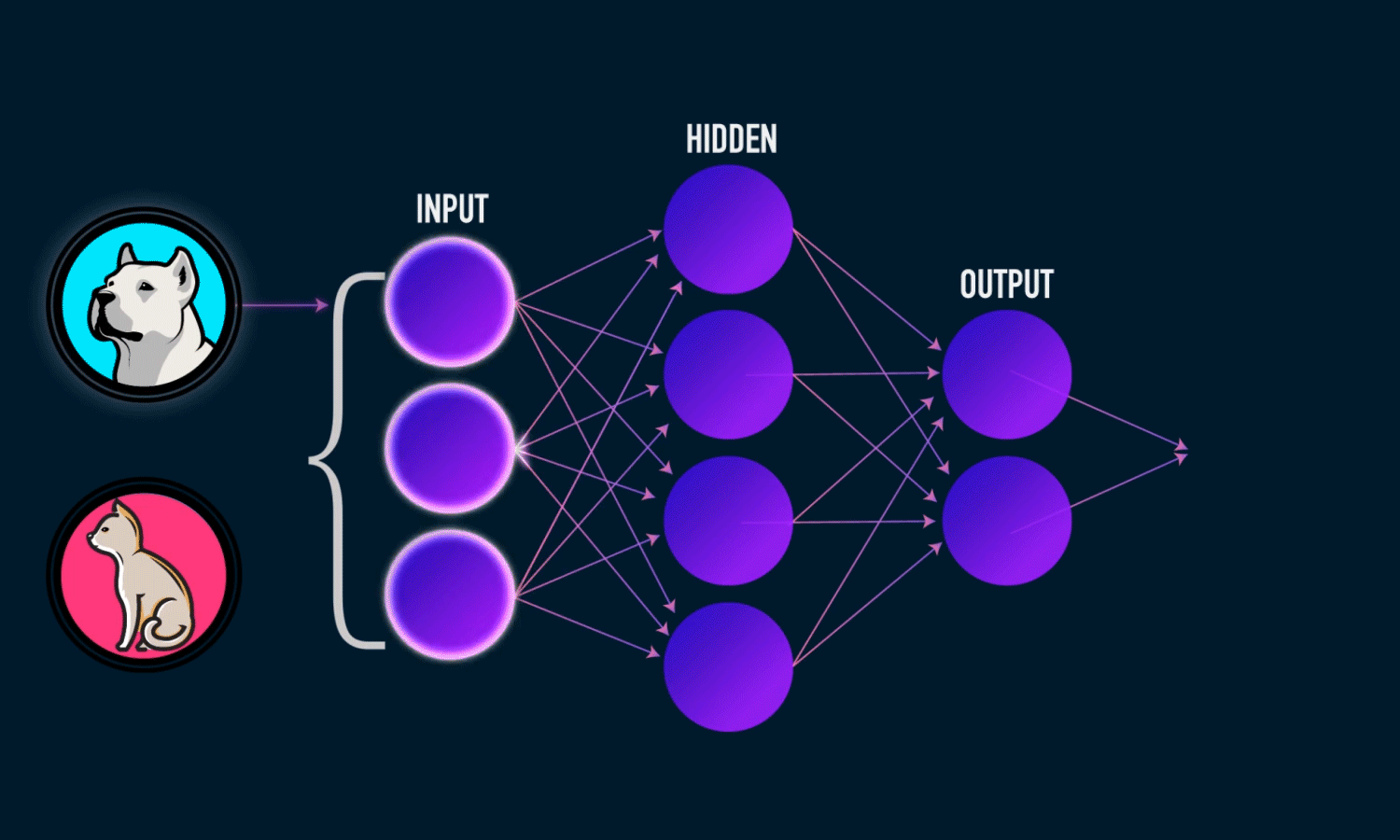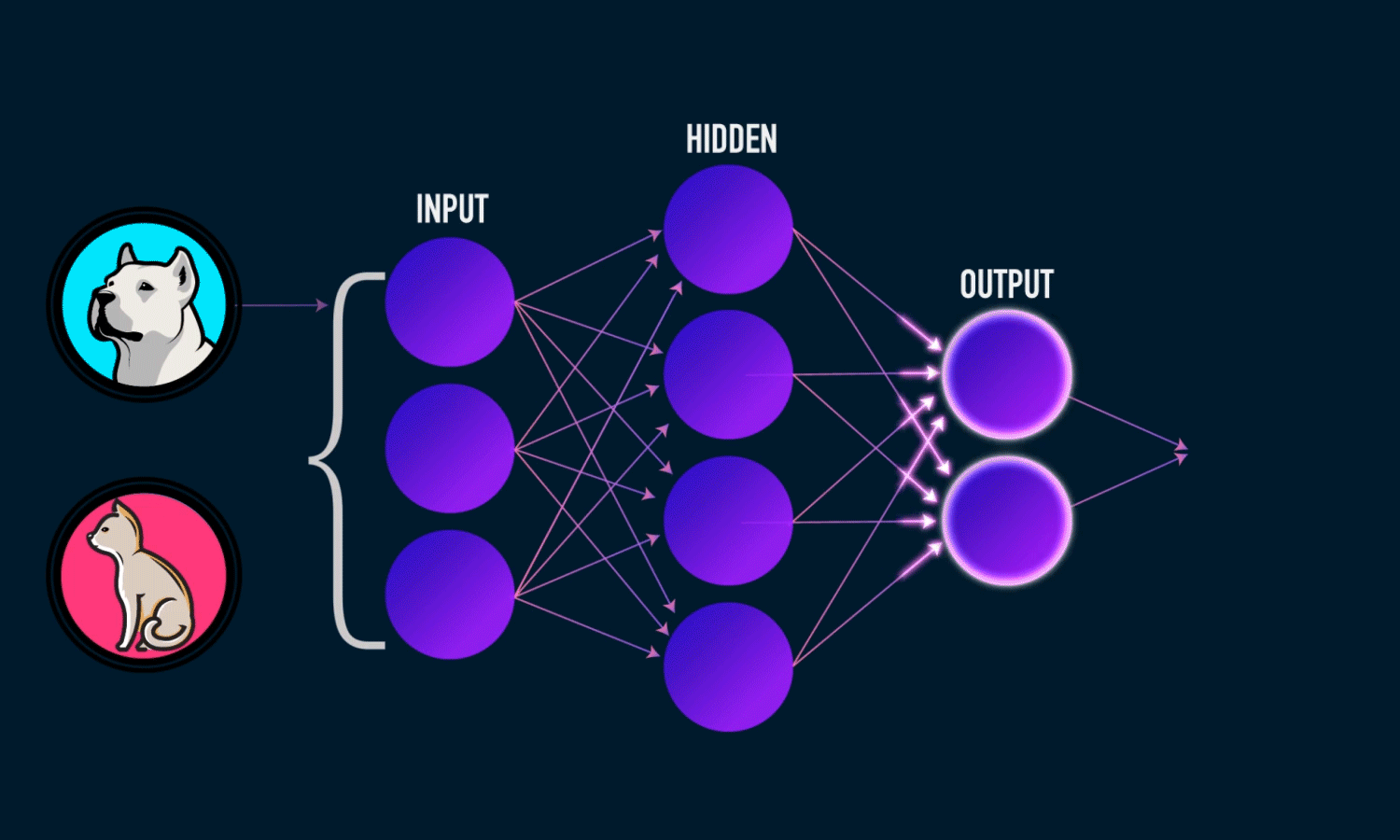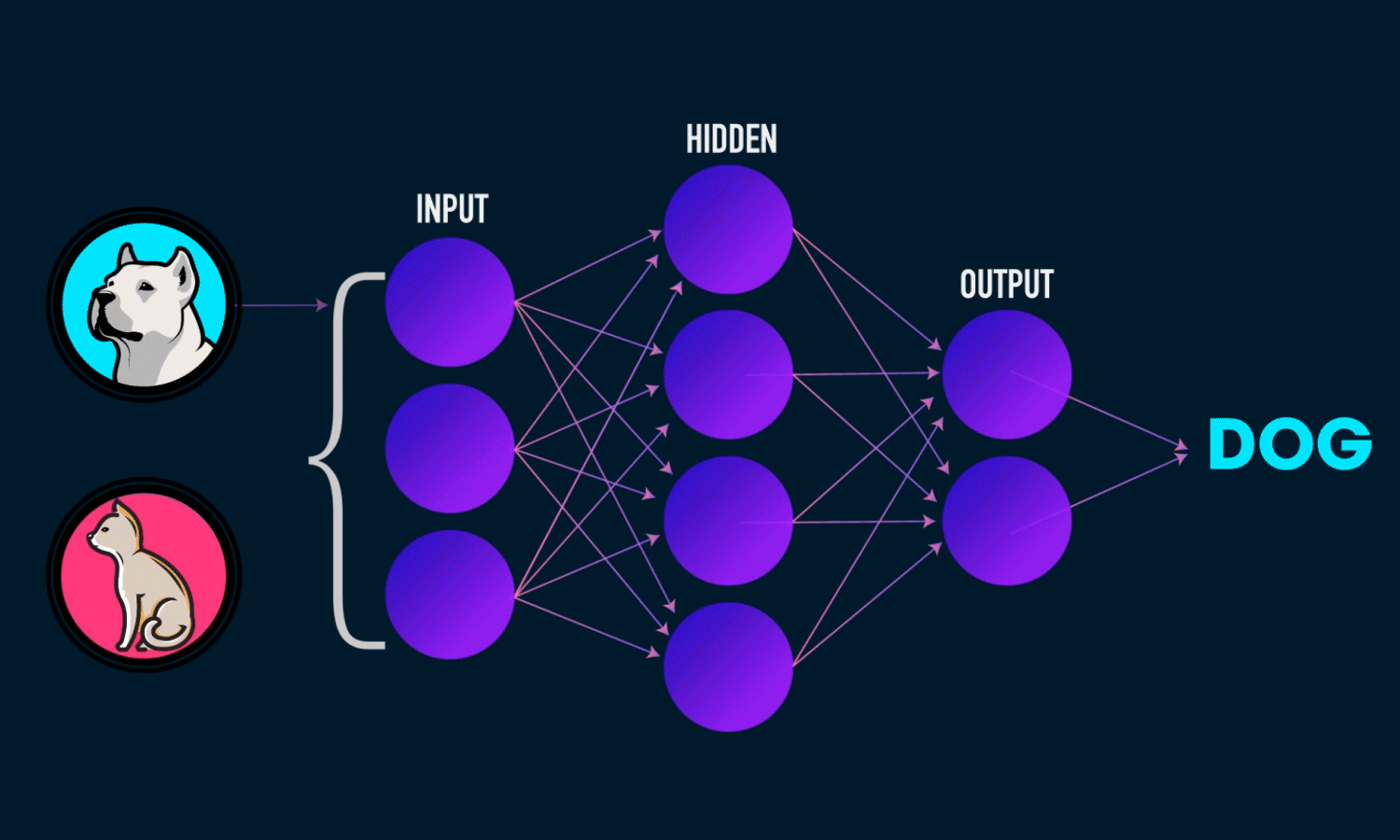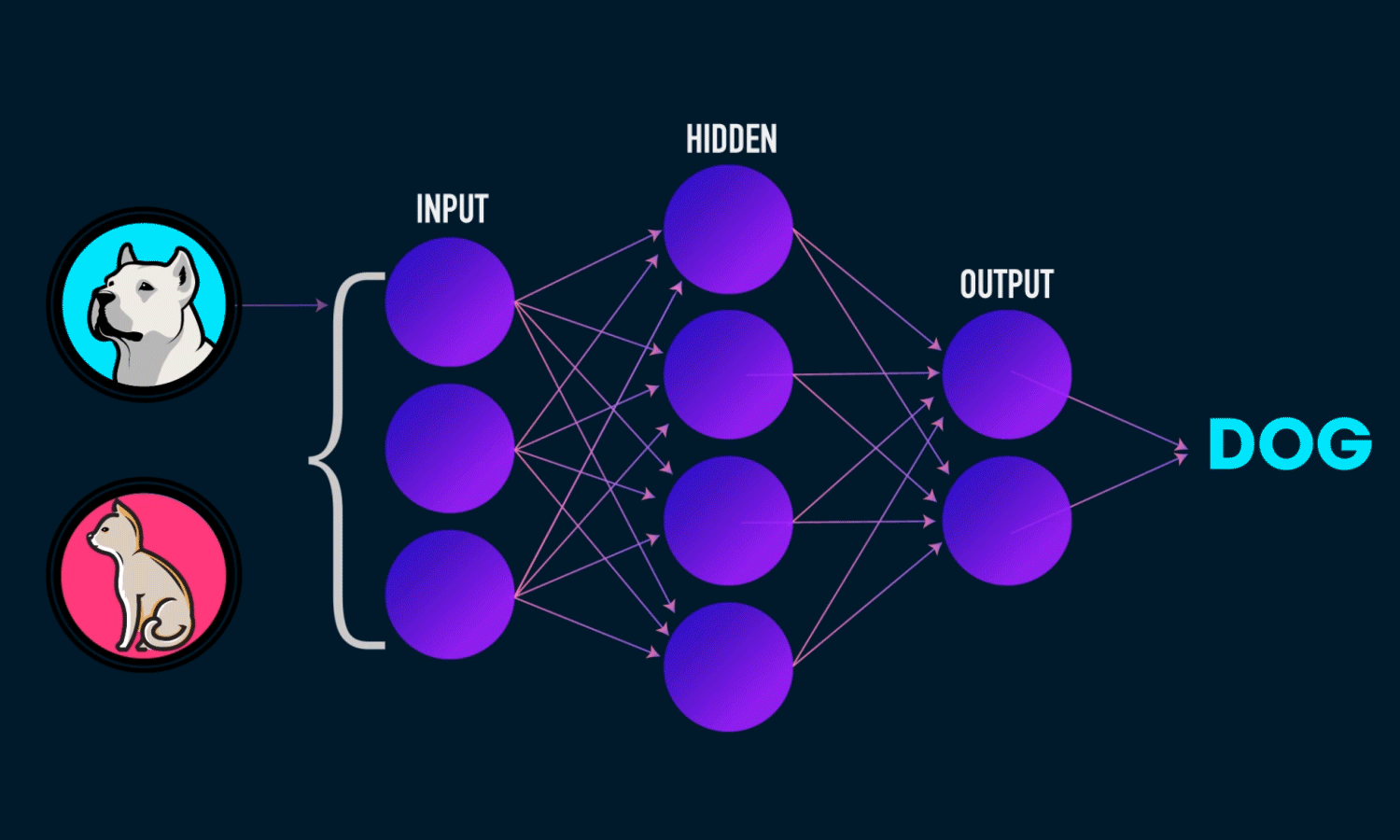
Convolutional Neural Networks can automatically find those features and classify the images for you.
A good CNN solution is required:
- To detect the objects in the image and place them into the appropriate category.
- To be robust against differences in pose, scale, illumination, conformation, and clutter.
Structure
CNN starts with an input image, extracts a few primitive features, and combines those features to form certain parts of the object. Finally, it pulls together all of the various parts to form the object itself. In essence, it is a hierarchical way of seeing objects; set of layers, with each of them being responsible to detect a set of feature sets.
In the deep learning process, we can see the following phases:
- Pre-processing of input data.
- Training the deep learning model
- Inference and deployment of the model.
Architecture
Besides multiple hidden layers, the type of layers and their connectivity in deep nets is also different compared to shallow neural nets. The layer types are: Convolutional, pooling and fully connected .
The convolutional layer applies a convolution operation to the input, and passes the result to the next layer. The pooling layer combines the outputs of a cluster of neurons in the previous layer into a single neuron in the next layer. And then, the fully connected layers connect every neuron in the previous layer to every neuron in the next layer.
The main purpose of the Convolutional layer is to detect different patterns or features from an input image, for example, its edges, by applying the filter to the image. Convolution is a mathematical function, simple matrix multiplication, that can detect edges, orientations, and small patterns in an image. Applying multiple kernels, i.e. filters, on one image will result in multiple convolved images. The output of the convolution process is called a feature map, because those are the initial feature extractions. We initialize the kernels with random values, and during the training phase, the values will be updated with optimum values (tweaked) in such a way that the image is recognized more accurately.
We can use ReLu (rectified linear unit) as the activation functions on top of nodes in the Convolution layer. ReLu is a nonlinear activation function, which is used to increase the nonlinear properties of the decision function, by mapping it to values between 0 and 1.
To down-sample the output from ReLu, we use another layer, Max-Pooling. “Max-Pooling” is an operation that finds the maximum values and simplifies the inputs, i.e. it reduces the number of parameters within the model.
The next layer is the Fully-Connected layer, which take the high-level filtered images from the previous layer and converts them into a one-dimensional vector. Then, it will be Fully-Connected to the next hidden layer. We call it Fully-Connected because each node from the previous layer is connected to all the nodes of this layer, through a weight matrix. It
We can use ReLu activation again here, to map the value between 0 and 1 and finally, use Softmax for classification. Softmax generates an output of multiclass categorical probability distributions.
Training
CNN is a type of feed-forward neural network, i.e. the information moves in only in one direction, forward, from the input nodes, through the hidden nodes and the output nodes. There are no cycles or loops in the network. The whole network is about a series of dot products between the weight matrices and the input matrix. The weight matrix is first initialized and then tweaked during the training process.
When we feed the network with a dataset of images, we compute the cost, i.e. the difference between the network’s predicted and actual output. The training process is called back propagation. During the training process, the weights and biases are tweaked, in a way that lowest cost, i.e. highest accuracy is achieved.
The Old problem
However, backprop faces the issue of the vanishing gradient. Gradient, is a measure of how much the cost changes respective to a change in a weight or bias. During backprop, the gradient decreases. It is first calculated at the output layer, then backwards across the net. Each gradient is the product of all the previous gradients up to that point. Since all the gradients are fractions between 0 and 1 the gradient continues to decrease. Higher gradient values lead to faster training, and lower gradient values to slower training. Since the layers near the input layer receive the smallest gradients,they take a very long time to train. Those initial layers are responsible for detecting the simple patterns and without properly detecting those, the complex image can’t be detected either. As a result, the overall accuracy suffers.
How to solve it?
There are several methods to overcome the problem:
- Deep belief network model, which use Restricted Boltzmann machine to model each new layer of higher level features.
- Faster hardware, which does not really overcome the problem in a fundamental way
- Residual networks, one of the newest and most effective ways to resolve the vanishing gradient problem. ResNets do this by utilizing skip connections, or short-cuts to jump over some layers. Skipping effectively simplifies the network, using fewer layers in the initial training stages.
